3차원 LiDAR 점군 데이터에서의 가상 차량 데이터 생성을 위한 구면 점 추적 기법

Copyright © 2023, The Korean Institute of Broadcast and Media Engineers
This is an Open-Access article distributed under the terms of the Creative Commons BY-NC-ND (http://creativecommons.org/licenses/by-nc-nd/3.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited and not altered.
초록
딥러닝 네트워크를 이용한 3차원 객체 인식 기술은 자율주행 기술 개발에 있어 대상 객체의 종류 뿐만 아니라 센서로부터의 거리도 인식할 수 있기 때문에 장애물 탐지를 위해 많이 개발되고 있다. 하지만 3차원 객체 인식 모델의 경우 원거리 객체에 대한 탐지 성능이 근거리 객체에 대한 인식 성능보다 낮아 차량의 안전을 확보하는 데에 치명적인 문제가 발생할 수 있다. 본 논문에서는 가상의 3차원 차량 데이터를 생성해 모델 학습에 사용되는 데이터셋에 추가하여 3차원 객체 인식 모델의 성능, 특히 원거리의 객체에 대한 성능을 향상시키는 기술을 소개한다. 3차원 라이다 센서 데이터의 특성을 활용한 구면 점 추적 기법을 사용하여 실제 차량과 매우 유사한 가상 차량을 생성하였고, 생성한 가상 차량 데이터를 사용하여 원거리뿐만 아니라 모든 거리 영역 범위에서의 객체 인식 성능을 향상시킴으로써 가상 데이터의 학습 유효성을 입증하였다.
Abstract
3D Object Detection using deep neural network has been developed a lot for obstacle detection in autonomous vehicles because it can recognize not only the class of target object but also the distance from the object. But in the case of 3D Object Detection models, the detection performance for distant objects is lower than that for nearby objects, which is a critical issue for autonomous vehicles. In this paper, we introduce a technique that increases the performance of 3D object detection models, particularly in recognizing distant objects, by generating virtual 3D vehicle data and adding it to the dataset used for model training. We used a spherical point tracing method that leverages the characteristics of 3D LiDAR sensor data to create virtual vehicles that closely resemble real ones, and we demonstrated the validity of the virtual data by using it to improve recognition performance for objects at all distances in model training.
Keywords:
Autonomous driving, LiDAR, Point Cloud, Object Detection, Data GenerationⅠ. 서 론
3D Object Detection 기술은 2차원 영상 데이터를 이용한 2D Object Detection에 비해 전방위에 대한 객체 인식이 가능하고, 인식한 객체에 대한 거리 정보까지 얻을 수 있기 때문에 자율주행 차량의 전후방 장애물 인식을 위해 개발되고 있다. 하지만 3차원 객체 인식 기술은 센서로부터 객체의 거리가 멀수록 탐지 성능이 떨어진다는 단점이 있는데, 이는 점군 객체가 거리에 따라 형상 변화폭이 커 모델 학습이 어렵고, 3차원 데이터의 수집 및 가공 난이도가 높아 학습용 데이터셋의 원거리 객체 데이터가 부족하기 때문에 발생하는 문제이다. 이를 해소하기 위해 3차원 객체 데이터를 임의로 생성하거나[1][2], 가상 환경을 생성해 학습용 데이터를 구성하는 등의 연구[3][4][5][6]가 제안되었지만, 이들은 센서 노이즈와 같은 실제 수집 환경의 여러 요소를 반영하지 않기 때문에 실제 데이터와는 차이가 있고, 가상 데이터의 가공 작업이 추가로 필요하다.
따라서 본 논문에서는 3차원 라이다 점군 데이터의 특성을 활용하여 입력 데이터의 점군을 센서 중심 방향으로 투영하는 구면 점 추적 기법을 개발해 실제 수집된 객체가 가지는 고유의 형상을 유사하게 구현해 내었다. 또한 가상 객체를 통해 증강한 데이터셋을 3D Object Detection 모델에 학습시켜 먼 거리뿐만 아니라 근거리의 객체에 대한 인식 성능이 향상되었음을 증명하였고, 이를 통해 가상 객체를 추가한 데이터셋을 이용하면 같은 모델에서 더 높은 학습 성능을 도출할 수 있음을 증명하였다.
Ⅱ. 구면 점 추적 기법
3차원 라이다 센서는 센서 중심으로부터 방사되어 직진하는 광선이 어떤 물체와 부딪힐 때, 반사되어 돌아오는 광선의 정보를 이용하여 물체의 형상을 탐지한다. 또한 센서로부터 방사되는 광선은 센서 성능에 따라 정해진 개수의 광선을 수직 분해능(Vertical Resolution) 만큼의 각 차이를 두어 방사하고, 이 방사 모듈을 수평 시야각(Horizontal Angle) 만큼 회전시켜 전 방위의 데이터를 수집한다. 이러한 라이다 센서의 구동 방식으로 인해, 수집 데이터의 각각의 점들은 센서 중심을 원점으로 하는 구면 좌표계 상의 좌표로 표현되고, 이는 곧 라이다 센서로 수집한 데이터가 가지는 고유의 형상 패턴을 만들어낸다. 그림 1은 라이다 센서의 수집 점군 데이터의 분포를 그림으로 표현한 것으로, 그림 1의 왼쪽과 같이 수집된 점군 데이터의 특정 영역을 확대하면 그림 1의 오른쪽과 같은 분포의 데이터를 확인할 수 있다.

360도 LiDAR 센서의 구동 특성에 의해 수집된 점군 데이터의 분포Fig. 1. Distribution of Point Cloud data by 360-degree LiDAR sensor
구면 점 추적 기법은 앞서 설명한 3차원 라이다 데이터의 객체 형상을 모사하기 위해 고안된 기법으로, 입력 데이터의 수집된 점들의 방사 경로를 추적하여 다시 센서 중심 방향으로 끌어와 원하는 형상의 가상 객체를 만들어내는 방식으로 동작한다.
우선 생성하고자 하는 객체(본 논문에서는 차량)의 데이터를 무수히 많은 점으로 표현된 Dense 객체 데이터로 생성한다. Dense한 객체 데이터는 3차원 그래픽스 모델링 분야에서 사용하는 OBJ 형식 모델링 파일을 PCD 형식의 점군 데이터로 추출하여 사용한다.
Dense한 차량 객체를 입력 데이터의 원하는 좌표에 생성한 후, 입력 데이터 상의 기존 점들의 방사 경로를 추적하여 센서 중심 방향으로 끌어온다. 이후 끌려오는 점들이 앞서 생성한 Dense 차량 객체와 충돌할 때, 충돌하는 위치의 3차원 좌표를 계산하여 새로운 점의 좌표로 덮어씌운다. 만약 추적 경로 상에 여러 개의 충돌 좌표가 존재할 경우, 좌표들 중 센서로부터의 거리가 가장 가까운 좌표를 선택한다. 그림 2는 그림으로 표현한 구면 점 추적 기법과, 구면 점 추적 기법의 실제 적용한 모습을 나타낸 것이다.

그림으로 표현한 구면 점 추적 기법(왼쪽)과 실제 구면 점 추적 기법을 적용한 모습(오른쪽)Fig. 2. Figure of Spherical Point Tracing(Left) and Application of Spherical Point Tracing Method(Right)
Ⅲ. 실험 및 결과
본 논문에서 제안하는 구면 점 추적 기법을 통해 3차원 라이다 점군 데이터 상의 가상 차량 데이터를 생성하였고 그림 3은 구면 점 추적 기법의 프로세스 별 가상 차량의 형상 변화와 생성된 가상 차량의 생성 거리별 형상을 나타낸 것이다. 사용한 기존 데이터셋은 KITTI 360 Dataset[7]을 사용하였고 KITTI 데이터셋의 라이다 센서인 Velodyne HDL-64E 모델의 성능을 입력 파라미터로 사용하여 생성하였으며 모델 학습 난이도 별로 나누어진 Easy, Mod, Hard Set으로 나누어 성능 평가를 진행하였다. 구면 점 추적 기법을 통해 거리가 멀어질수록 점군 분포가 Dense해지는 실제 객체 데이터의 형상을 유사하게 모사할 수 있다.

구면 점 추적 기법을 통해 생성한 가상 차량 객체의 생성 과정과 생성된 가상 차량의 거리에 따른 형상 변화Fig. 3. Generation process of Synthetic vehicle object via Spherical Point Tracing method and shape variation of synthetic vehicle according to distance
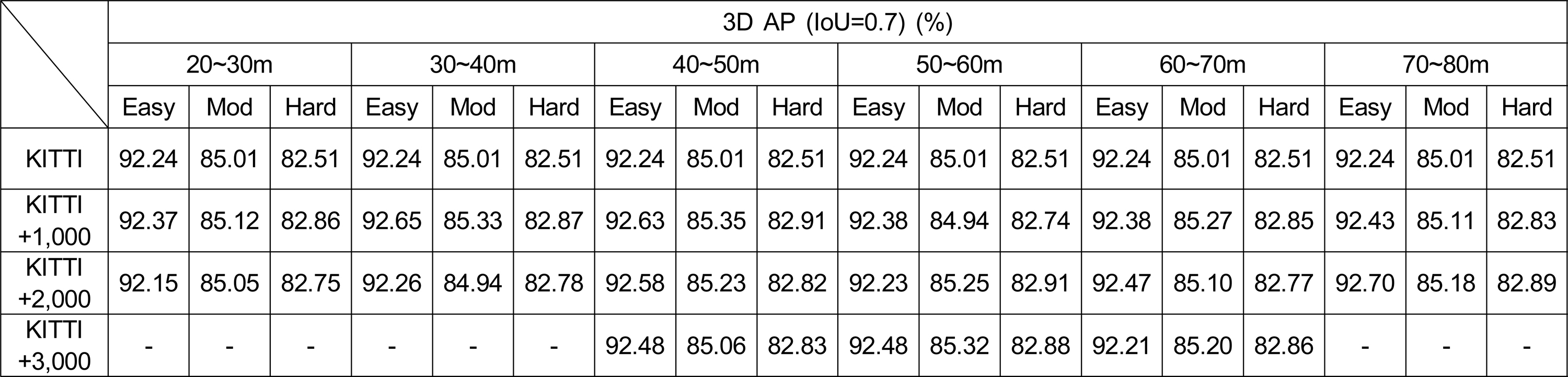
또한 KITTI 360 Train Set에 구면 점 추적 기법을 사용해 거리에 따라 나뉜 10m 단위 구간별로 가상 객체를 생성하고, 수를 1,000개 단위로 각각 다르게 생성하여 이를 Voxel R-CNN[8] 모델을 학습시켜 KITTI 360 Val Set에 대한 거리별, 생성 개수별 학습 성능 향상 폭을 측정하여 제안 기법으로 생성한 가상 객체 데이터의 유효성을 증명하였다.

센서와의 거리별 생성된 객체의 개수에 따른 Voxel R-CNN 모델의 학습 성능 변화Table 1. Performance improvements of Voxel R-CNN on the KITTI val set with Synthetic KITTI dataset by distance
실험 결과 근거리에서는 비교적 적은 개수, 원거리에서는 상대적으로 많은 수의 가상 객체를 생성했을 때 학습 성능이 향상됨을 보였다. 다만 무조건적으로 많은 수의 증강보다는 영역별 적당한 개수의 가상 객체 생성이 성능 향상에 더욱 크게 기여하는 것으로 분석된다.
Ⅳ. 결론
본 논문에서는 구면 점 추적 기법을 사용한 가상 차량 객체 생성 기술을 소개한다. 제안하는 기법을 이용하여 실제 3차원 라이다 센서의 수집 데이터와 동일한 형상을 가지는 가상 객체를 생성하였고, 생성된 가상 객체로 데이터셋을 증강하여 3차원 객체 인식 모델의 학습 성능을 향상시킴으로써 가상 객체의 유효성을 증명하였다.
Notes
References
-
Wang, F., Zhuang, Y., Gu, H., Hu, H., Automatic Generation of Synthetic LiDAR Point Clouds for 3-D Data Analysis, IEEE Trans. of Instrumentation and Measurement, (2019, July), 68(7), p2671-2673.
[https://doi.org/10.1109/TIM.2019.2906416]

-
Chitnis, S., Huang, Z., Khoshelham, K., Generating Synthetic 3D Point Segment for Improved Classification of Mobile LiDAR Point Clouds, The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, (2021), p139-144.
[https://doi.org/10.5194/isprs-archives-XLIII-B2-2021-139-2021]
-
Beltrán, J., et al. , A Method for Synthetic LiDAR Generation to Create Annotated Datasets for Autonomous Vehicles Perception, 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, (2019), p1091-1096.
[https://doi.org/10.1109/ITSC.2019.8917176]
-
Hossny, M., Saleh, K., Attia, M., Abobakr, A., Iskander, J., Fast Synthetic LiDAR Rendering via Spherical UV Unwrapping of Equirectangular Z-Buffer Images, Computer Vision and Pattern Recognition, Image and Video Processing, (2020, June).
[https://doi.org/10.48550/arXiv.2006.04345]
-
Yue, X., et al. , A LiDAR Point Cloud Generator: from a Virtual World to Autonomous Driving, Computer Vision and Pattern Recognition, (2018, June), p458-464.
[https://doi.org/10.1145/3206025.3206080]
-
Yoon, S., et al. , Development of Autonomous Vehicle Learning Data Generation System, The Journal of The Korea Institute of Intelligent Transport Systems, The Korea Institute of Intelligent Transport Systems, (2020), 19(5), p162-177.
[https://doi.org/10.12815/kits.2020.19.5.162]
-
Geiger, A., Lenz, P., Urtasun, R., Are we ready for autonomous driving? The KITTI vision benchmark suite, 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, (2012), p3354-3361.
[https://doi.org/10.1109/CVPR.2012.6248074]
-
Deng, J., Shi, S., Li, P., Zhou, W., Zhang, Y., Li, H., Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection, Proceedings of the AAAI Conference on Artificial Intelligence, (2021, May), 35, p1201-1209.
[https://doi.org/10.1609/aaai.v35i2.16207]
-
Rusu, R. B., Cousins, S., 3D is here: Point Cloud Library (PCL), 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, (2011), p1-4.
[https://doi.org/10.1109/ICRA.2011.5980567]
-
Zhou, Q., Park, J., Koltun, V., Open3D: A Modern Library for 3D Data Processing, (2018).
[https://doi.org/10.48550/arXiv.1801.09847]