
미디어 창작을 위한 공공스톡 비디오 아카이브에서의 검색 지능화 현황 및 적용 연구

Copyright © 2025 Korean Institute of Broadcast and Media Engineers. All rights reserved.
“This is an Open-Access article distributed under the terms of the Creative Commons BY-NC-ND (http://creativecommons.org/licenses/by-nc-nd/3.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited and not altered.”
초록
미디어 창작을 위해 콘텐츠를 창작의 소재로 제공하는 서비스는 콘텐츠 제작사와 유통사를 위주로 제공되고 있으며, 서비스 기능을 향상하는 연구도 진행되고 있다. 본 연구는 창작자를 위한 공공스톡 아카이브의 접근성을 개선하기 위해 검색 지능화 방법론을 조사하고 적용 사례를 제안한다. 즉, 공공 및 스톡 아카이브의 국내외 사례 조사를 통해 인공지능 기술 발전을 활용한 검색 지능화 방법론을 정리하고, 이 방향성에 맞는 적용 방안을 고찰한다. 그리고 ‘KBS바다’ 오픈아카이브 기반으로 고찰한 창작자들의 요구를 만족시키고, 방향성에 적합한 검색 지능화 구현 사례를 제시한다. 제안된 시스템은 검색 정확성과 사용 편의성을 높이고, 타임라인 기반 메타데이터 및 텍스트 검색 기능을 통해 원하는 콘텐츠에 대한 접근성을 개선한다. 검색 지능화는 비디오 요약 생성, 태그 자동화, 개인화된 콘텐츠 제작 등 다양한 활용 가능성을 열어, 창작자들에게 새로운 가치와 가능성을 제공할 것으로 기대된다.
Abstract
Services that provide content as creative material for media production are primarily offered by content creators and distributors, with ongoing research aimed at enhancing service functionalities. This study investigates and proposes applications of intelligent search methodologies to improve the accessibility of public stock archives for creators. By analyzing domestic and international cases of public and stock archives, the study outlines search intelligence methodologies leveraging advancements in artificial intelligence technologies and examines implementation strategies aligned with these approaches. Specifically, the research considers the needs of creators and presents a case of implementing intelligent search methods based on the ‘KBS BADA’ Open Archive that meet these demands. The proposed system enhances search accuracy and usability while significantly improving accessibility to desired content through timeline-based metadata and text search functionalities. Intelligent search opens up diverse possibilities, such as video summarization, tag automation, and personalized content creation, offering new value and opportunities for creators.
Keywords:
Public stock video archives, Intelligent search, Media description, Media creation, Content accessibilityⅠ. 서 론
플랫폼 서비스 위주의 미디어 이용 증대와 대표적인 오픈 미디어 플랫폼 서비스인 유튜브의 이용 활성화는 1인 미디어라는 새로운 키워드를 생성했을 뿐 아니라, 광고 수익의 배분으로 인해 창작자 1인이 미디어의 창작자, 중개자, 소비자의 3가지 역할을 거부감없이 동시에 수행하는 트렌드를 만들었다[1]. 개인의 근황을 지인에게 전하던 소셜미디어의 경우, 인스타그램(Instagram), 틱톡(TikTok), 유튜브(YouTube) 서비스 등의 사례에서 보듯이, 이제는 숏폼 영상 콘텐츠의 형태로 메시지를 전달하는 것이 주요 형태가 되었다. 이러한 비디오 메시지 표현의 일반화와 창작자의 양산은 다양한 주제의 대량 콘텐츠가 생산되는 환경을 만들었으며, 창작을 위한 더욱 많은 소재 콘텐츠의 발굴과 창작 효율화를 위한 생성형 인공지능(Artificial Intelligence) 기술 사용의 확대로 이어지고 있다[2][3].
콘텐츠 제작사, 미디어 플랫폼사의 종사자나 개인 창작자들은 창작 활용이 가능한 형태로 창작의 결과물을 수집하고 활용할 수 있게 하는 아카이브 서비스를 원하고 있으며, 이에 대한 정책적, 재정적 지원이나 서비스 요구사항들을 분석하는 연구들이 제안되었다[4]~[6]. 한국방송공사(KBS)는 이러한 전국민적 요구에 부응하기 위해 2022년 3월, 전 국민 대상으로 콘텐츠의 자유로운 활용이 가능한 무료 콘텐츠 클립 공개 서비스를 오픈하였다. ‘KBS바다’라고 명명한 서비스는 콘텐츠 제작, 학습, 교육, 연구에 짧은 고품질 소재 콘텐츠를 활용할 수 있도록 하는 오픈 스톡 서비스이다[7]. 비디오 아카이브 활용을 극대화하기 위한 검색 기능의 근간에는 KBS에서 제정한 메타데이터 표준화를 준수하는 메타데이터 전문 인력의 메타데이터 입력 작업이 중요한 역할을 하고 있다[8].
방송이나 OTT 플랫폼 서비스를 통해 유통된 콘텐츠나 여기에 사용된 소재 콘텐츠들을 교육, 연구, 창작 활용이 가능한 형태로 공개하는 공공영상 아카이브의 대표적인 해외 사례는 BBC의 ‘크리에이티브 아카이브(Creative Archive)’, NHK의 ‘창의적 라이브러리(Creative Library)’, 프랑스의 ‘INA(Institut National de l'Audiovisuel)’가 있다. BBC의 ‘크리에이티브 아카이브’는 BFI(British Film Institute), Channel 4, Open University가 결성한 크리에이티브 아카이브 라이선스 그룹에서 만든 서비스로, BBC의 풍부한 아카이브를 대중에게 개방함으로써 영국의 문화유산에 대한 접근성을 향상시키고, BBC의 콘텐츠를 활용하여 새로운 창작물을 만들거나 학습 자원으로 활용할 수 있도록 장려하는 목적으로 시작하였다. 프랑스의 ‘INA’는 프랑스 국립시청각연구소로서, 영상관련 자료의 수집 및 보관, 영상 리소스를 위한 새로운 제작 기술의 연구·교육·보급 등의 임무를 맡고 있는 프랑스 최대의 영상 자료보존기관이다[9]. INA 산하의 Inathèque는 프랑스의 방송법을 근거로 공·민영의 모든 방송사(단, 지역 민영 라디오와 위성방송 제외)에서 제작·방영되는 모든 프로그램을 의무적으로 납본을 받아 소장 자료에 대한 열람 서비스를 제공하고 있다[9]. NHK 창의적 라이브러리는 일본의 풍부한 방송 콘텐츠와 문화유산을 대중에게 개방하고, 이를 통해 창의적인 활동을 촉진하는 플랫폼으로, 디지털 시대에 공영방송이 제공하는 온라인 서비스이다. 동영상, 음성 클립 등 다양한 미디어 자료를 대상으로, 비상업적 목적으로만 활용할 수 있으며, 검색 방법은 썸네일 이미지 색상, 텍스처 패턴, 구성 등을 활용한 유사성 검색 기술을 통합하여 사용자가 원하는 개념적 이미지에 가까운 영상을 찾을 수 있도록 지원한다[9].
스톡 아카이브 서비스는 미디어 작업에 소요되는 창작자들의 시간과 노력을 줄여주기 위해 고해상도, 로열티프리의 동영상, 이미지, 음악 등을 제공하는 서비스이다. 서비스 제공자는 창작자들이 일반적으로 요구하는 시장성이 높은 콘텐츠를 만들어 제공하는 것을 목표로 하며, 작업에 집중할 수 있도록 적절한 키워드를 제공하여 손쉽게 콘텐츠를 검색할 수 있는 것을 목표로 한다. 대표 스톡 서비스인 Shutterstock[10], Getty Images[11], Adobe Stock[12], Unsplash[13], Pexels[14] 등에서는 효과적인 검색을 위해 다양한 가이드라인을 제공하고 있으며, 검색 제공 방법에 있어서도 미디어 분석 및 인공지능 기술을 활용한 검색 방안도 연구되고 있다. 이 서비스들은 높은 품질과 다양한 이미지, 비디오, 음악 등을 제공하는 서비스로 알려져 있으며, 검색 기능으로는 카테고리 검색과 인기 키워드 검색을 주로 제공하고 있다.
공공성을 기조로 하는 공공영상 아카이브 서비스에서의 주요 기능은 수집과 보존을 기본으로 하는 장기보존과 지속적인 접근성 보장의 두 가지로 정리되고 있다[15]. 이미 방송된 방송프로그램을 검색하기 위해 프로그램명, 방송시간, 부제명, 출연자 등 방송사에서 사용하는 방송프로그램 제작 정보와 편성 정보를 준용하여 표준화된 메타데이터 표준과 분류체계 표준을 검색에 활용하는 것은 방대한 콘텐츠에 일원화된 검색 방법을 제공할 수 있어 원하는 콘텐츠를 검색하는데 효과적이다. KBS에서도 메타데이터와 분류체계를 표준화하여 이에 기반으로 콘텐츠를 아카이브에 보존하고 있으며, 유통 표준의 일환으로 제안하여 표준화하였다[16]. 그러나 다수의 제작사, 플랫폼사, 개인이 창작한 콘텐츠를 아카이브화하여 서비스하기에는 제작사별, 플랫폼사별 아카이브가 이미 존재하여 일원화된 체계를 공유하기 어렵고, ‘KBS바다’와 같이 방송프로그램의 소재로 사용된 소재 콘텐츠를 검색하는 경우는 정제된 제작 정보와 편성 정보를 사용할 수 없는 경우가 존재한다. 다양한 아카이브와 다양한 콘텐츠를 대상으로 하는 공공스톡 아카이브에서 창작자들이 요구하는 접근성을 보장하는 것은 메타데이터, 사용자 인터페이스, 통합 검색 기능, 시스템 연계 등 다양한 측면의 고찰이 필요하다.
미디어 분야의 인공지능 기술 활용 근간을 마련하는 ‘미디어 지능화’는 ICT 핵심기술과 융합을 통해 대용량의 수집·저장된 데이터(Data)를 분석하여 의미 있는 정보(Information)를 생성하고, 생성된 정보를 효과적으로 사용자에게 전달(Media)하는 D-I-M(Data-Information-Media)의 지식 가치사슬을 완성하는 지능화 시대의 핵심 인프라로 정의하였다[17]. 또한, 미디어 지능화 상에서 구현된 스톡 아카이브의 방대한 콘텐츠 검색을 위해 전문 인력이 판단하거나 정보를 입력해야 하는 과정을 최대한 자동화하여 검색 기능을 제공하는 것을 ‘검색 지능화’라고 정의하였다 [18]. 본 논문에서는 ‘검색 지능화’의 정의를 확장하여, 인공지능 기술을 활용하여 사용자의 검색 경험을 접근성 측면에서 향상하는 일련의 방법까지를 ‘검색 지능화’라고 포괄적으로 정의한다. 본 논문에서는 공공스톡 아카이브에서 창작자들의 접근성 보장을 위해 고려해야 하는 요구사항과 각 측면에서 사용되고 있는 진화하는 인공지능의 방법들을 활용한 검색 지능화 방법론과 사례들을 창작자들의 요구사항 분석에 근거하여 고찰한다. 또한, ‘KBS바다’를 대상으로 구현한 검색 지능화 적용 사례를 통해 검색 지능화 방법론의 측면에서 구현 방안을 제안하고, 제안한 방법의 사용자 사용 경험을 통해 접근성 측면의 사용성을 분석한다.
본 논문의 구성은 다음과 같다. 2장에서는 창작을 위한 콘텐츠를 제공하는 대표 공공 아카이브와 스톡 아카이브를 대상으로 접근성의 측면에서 검색 지능화 방법론을 조사 분석한다. 3장에서는 공공스톡 아카이브인 ‘KBS바다’를 대상으로 구현한 검색 지능화 사례를 통해 2장에서 제안한 검색 지능화 방법론의 적용 방안을 제시한다. 4장에서는 창작자를 대상으로 한 개방 시범서비스 결과 분석을 통해 접근성 측면의 사용성 분석 결과를 고찰한다. 5장에서는 검색 지능화의 향후 발전 방안을 제시한다.
Ⅱ. 콘텐츠 접근성 측면의 검색 지능화 방향성 조사 연구
콘텐츠 제작사, 미디어 서비스 플랫폼사의 종사자나 개인 창작자들은 창작 활용이 가능한 형태로 창작의 결과물을 수집하고 활용할 수 있게 하는 아카이브 서비스를 원하고 있다[4]~[6]. 공공 아카이브의 구축과 활용을 요구하는 창작자들은 사용과 구매 과정에서 접근성 측면의 불편을 겪었으며, 해결 방안이 제시되어야 한다는 연구가 있다[9]. 불편 사항을 정리해 보면, 다음과 같다. 첫째, 콘텐츠에 대한 메타데이터가 체계적이지 않거나 상세 가이드라인이 제공되지 않아 검색이 어렵고, 검색을 성공적으로 수행해도 작업 효율성에 영향을 주는 클린본, 편집본, 영상 포맷 등 자료의 형태나 단위에 대한 상세 정보가 제공되지 않는 경우가 많다. 둘째, 프리뷰를 제공하지 않거나, 콘텐츠를 찾을 수 있을 정도의 방법이 제공되고 있지 않다. 셋째, 자료 다운로드 기능이 제공되지 않거나, 원하는 부분을 정확히 받기 어렵다. 넷째, 화질이나 사용에 대한 저작권 해결 등 제공받은 영상의 품질 관리를 보장받을 수 없다. 방송사 제작자들의 경우에는, 검색 키워드 입력으로 빠르게 영상 콘텐츠 검색의 1차 결과를 받아보는 것에 불편을 느끼지 못하며, 상세 조건 입력, 검색 결과 내 날짜 등의 추가 조건 입력을 통한 재검색 등 1차 결과 내에서 검색 결과 범위를 축소하는 검색 편의 기능을 추가하는 요구사항이 있었다[8]. 요약하면, 클립 단위의 아카이브를 사용해 본 창작자들은 영상 콘텐츠에 대한 정보인 메타데이터를 기반으로 키워드 검색을 체계화거나, 다양한 정보를 제공함으로써 원하는 콘텐츠를 신속하고, 정확하게 찾는 방법을 제공해 주기를 요구하고 있다. 또한, 프리뷰의 형태로 콘텐츠 내용을 확인하는 방법을 제공하거나, 이때 활용에 적합한 클립 형태인지 알 수 있는 정보도 함께 제공하기를 요구한다. 그 외, 다운로드 시 활용하고자 하는 부분을 선별하여 제공하는 기능과 활용에 제약이 없도록 저작권 해결도 확인해 줄 것도 요구하고 있다.
위 요구사항에서 검색을 체계화하거나 풍부한 정보를 제공하는 것은 본 논문에서 조사하고 고안한 검색 지능화의 진전으로 점점 검색 경험이 향상되고 있고, 다운로드 방법이나, 검색 결과 확인, 저작권 해결 등은 기능 구현이나 관리 정책으로 제공할 수 있다. 최근, 콘텐츠의 검색은 인공지능 기술의 활용으로 새로운 검색 경험에 대한 접근 방법이 시도되고 있다. 예를 들면, Netflix의 경우는 제작의 과정에서 발생한 정보를 모두 확보하기 위해 제작사들이 메타데이터를 입력하는 비용까지도 지불하여 잘 정리된 메타데이터를 납품받고 있다[5]. 대표적인 스톡 아카이브의 경우도 이미 정한 카테고리를 공개하고, 콘텐츠 업로드 시에 해당 카테고리를 입력하도록 안내하고 있으며, 업로드 포털시스템에서 인공지능이 자동으로 카테고리를 추천하는 기능도 제공하고 있다[19][20]. ChatGPT[21] 공개 이후 프롬프트라 불리는 대화형 검색이 수행되고 있다. 인공지능 기술과 결합한 검색 방법의 개선은 새로운 검색 경험을 제공하며, 창작 과정을 효율화하고 있다. 최근 검색 지능화는 어떤 방법으로 진화하고 있는지 대표 스톡 아카이브 서비스와 미디어 플랫폼사, 검색 서비스 사들의 관련 서비스들을 조사 연구하였으며, 그 방향성은 다음과 같이 4가지로 정리해 볼 수 있다.
1. 콘텐츠 분류 체계화로 다양한 상세 메타데이터 제공과 검색 활용
Netflix의 경우, 자체 개발한 태거(Tagger) 시스템을 약 30명으로 구성된 전문가 그룹이 사용하여 메타데이터와 장르를 입력한다. 전문가 그룹은 방대한 Netflix의 태깅 정책 자료를 교육 받고, 모든 콘텐츠를 직접 시청하고 상세한 태그를 입력한다. 태그의 종류는 표 1과 같고, 1,000개 이상의 기본 태그를 조합하고, 지역, 수식어, 장르, 원작, 배경, 시대, 주제, 나이에 해당하는 마이크로장르 구성 요소를 이용하여 적합한 76,897개에 달하는 마이크로장르를 할당한다. 생성한 마이크로장르의 예시는 “악마 같은 아이가 나오는 컬트 공포 영화”, “유럽 배경의 60년대 영국 공상과학/판타지물”, “비평가들에게 호평받은 감동적 패배자 영화” 등과 같다. 이러한 정교한 태깅 시스템과 마이크로장르를 통해 Netflix의 성공을 견인한 사용자에게 매우 개인화된 콘텐츠 추천을 제공할 수 있다.

Examples of Netflix Tag Types
Adobe Stock의 경우, 스톡의 창작자들이 원하는 콘텐츠를 손쉽게 검색하여 시장성을 높이기 위해 스톡의 업로더들이 입력해야 하는 제목, 키워드 입력 가이드라인과 적절한 범주를 선택하는 가이드라인을 상세히 안내하고 있다[19][20]. 즉, 제목 작성은 창작자들의 구매 결정에 도움이 되는 제목을 작성하기 위해 특정 제품명이나 사람 이름은 포함하지 않고, 간결하게 작성하는 것을 권장하고 있다.(제목 사례 : “미국 오리건주 포틀랜드의 한 해변에서 잭 러셀 테리어와 캐치볼을 하고있는 젊은 여성”) 또한, 키워드 작성은 피사체, 동작, 피사체의 설정, 중요 구성 요소 등으로 구성하고, 위치, 감정, 분위기, 사용자수, 설정, 시점, 인구통계학정보 등도 포함하는 것을 권장하고 있다.
미리 제공되는 콘텐츠에 대한 정보를 기반으로 수행하는 카테고리 검색은 사용자와 서비스 제공자 간 분류체계에 대한 공유가 필요하고, 비디오와 같이 하나의 콘텐츠 파일에서 특정 장면이나 일부분만을 창작에 사용하고자 할 때, 특정 부분을 찾아내기 위해 결국 하나의 콘텐츠 파일을 모두 시청해 확인해야 하는 작업이 수반되어, 추가적인 노력이 필요하다는 단점이 있다. 조사된 대표 사례에서는 현재 입수된 비디오를 어느 카테고리에 할당해야 할지는 분류체계와 콘텐츠 내용의 매칭 작업에 숙련된 전문가나 창작자의 수작업이 필요하다. 그러나, Adobe Stock의 경우 업로드된 영상 콘텐츠의 카테고리 추천을 인공지능 기술을 사용하여 수작업을 줄이는 방향으로 진전하고 있다.
2. 대화형 질의에 따른 문맥 이해와 질의의도 파악
대화형 검색은 단순한 키워드 매칭 위주의 검색 방법과 달리, 사용자의 질의의 맥락과 의도를 이해하고, 이에 대한 적절한 응답 형태로 검색 결과를 생성하는 검색 방식이다. LLM(Large Language Model)에 기반한 ChatGPT, Gemini[22] 같은 대화형 인공지능 기술은 사용자의 이전 질의를 저장하고, 새로운 질의에 대해 이전 대화와의 문맥을 이해하여, 사용자의 질의 의도를 파악한다. 이는 키워드를 색인해 놓고, 매 질의마다 이 색인어와의 매핑을 계산하는 이전 질의 방법과는 다르다. 이러한 특징으로 ChatGPT와 Gemini는 사용자와 상호작용을 하면서 질문의 의도에 더 근접한 검색 결과를 제공한다.
3. 멀티모달 데이터를 활용한 다양한 정보 수집과 활용
멀티모달 검색은 텍스트, 이미지, 음성 등 여러 형태의 입력을 동시에 처리하여 얻은 정보를 종합적으로 분석함으로써, 사용자의 검색 의도와 맥락을 더욱 정확하게 이해하는 방법이다. 또한, 텍스트 위주의 검색과 달리 질의 자체와 검색 결과의 형태도 텍스트와 이미지, 비디오 등을 조합하여 직관적으로 생성할 수 있어, 이커머스, 콘텐츠 추천, 정보 검색 등 다양한 산업 분야와 사용 사례에 적용할 수 있는 높은 확장성과 사용자에게는 편리한 검색 경험을 가진다. 대표적인 사례인 [25]의 연구에서는 비디오 기반 멀티모달 이해를 위한 비디오 파운데이션 모델로 InternVideo2 모델을 제안하고, 해당 모델에서 1) 비디오의 시공간 정보를 학습하고, 2) 비디오를 텍스트, 오디오, 스피치 등 다른 모달 정보와 종합적으로 분석하여 의미적인 연관 능력을 확대하며, 3) LLM(Large Language Model)과 연결하여 비디오를 중심으로 비디오와 텍스트를 매핑해 대화 및 생성 능력 향상하는 방안을 제시하였다. 멀티모달 검색의 대표적인 사례인 InternVideo2 방법은 1) 비디오, 텍스트, 오디오, 스피치 간 멀티모달 데이터 정보 통합 분석 능력을 크게 향상시켜 보다 직관적이고 정확한 검색이 가능하게 하였고, 2) 시공간 정보를 정확히 복원함으로써 장면 간 전환이나 특정 동작을 구체적으로 이해 가능하고, 3) 비디오 중심 검색을 대화형으로 가능하게 하는 기초를 제공하고 있다.
4. 개인의 검색 기록과 선호를 활용한 맞춤 검색
ChatGPT와 Gemini같은 대화형 검색은 개인의 질의 기록과 패턴을 저장, 분석하기 때문에 사용자의 관심사와 선호도를 고려한 검색 결과를 제공하거나, 사용자의 행동 패턴에 기반한 추천 결과도 제공한다. 이는 사용자 개인화된 맞춤 결과를 제공하게 된다. Gemini의 다단계 추론 기능은 질문을 나누어 여러 번 검색할 필요 없이, 모든 뉘앙스와 조건을 반영한 가장 복잡한 질문도 한 번에 물어볼 수 있습니다. 예를 들면, Google사의 Search Labs 서비스에서 “보스턴에서 가장 좋은 요가 또는 필라테스 스튜디오를 찾아서, 그 곳은 어떤 곳인지, 또 비컨 힐에서 도보로 얼마나 걸리는지, 제공하는 혜택은 무엇인지 자세히 알려줘”라는 한 번의 검색으로 지역 주민들에게 인기 있고, 접근하기 편리한 위치에 있으며, 신규 회원 대상 할인 혜택을 제공하는 새로운 요가 또는 필라테스 스튜디오를 찾는 답변을 얻을 수 있다. 또한, Gemini의 계획 기능은 “준비하기 쉬운 3일치 그룹 식단 계획을 만들어 줘”라고 구글 검색에 입력하면, 웹 상의 다양한 레시피를 시작점으로 작성된 식단 짜기부터 운동 루틴 만들기, 휴가 계획과 파티 계획까지 모든 종류의 계획을 검토할 수 있도록 제시한다. 계획의 일부 수정도 수정 내역을 입력하면 변경된 내용에 맞는 결과를 주게 된다.
본 장에서 조사 분석한 검색 방법론의 진화 방향은 문맥에 대한 이해, 멀티모달 정보수집, 개인의 선호도 등과 연관된 정보들을 통합하여 수집하고, 이를 문맥에 따라 재조합하여 검색의 경험을 확장하고 있다. 예를 들면, 한 장면의 내용을 검색할 때, 시공간 정보를 활용해 이전 장면의 내용과 이후 장면의 내용을 종합적으로 판단함으로써 검색의 정확성과 효율성을 향상시키고, 사용자에게 더욱 관련성 높고 유용한 정보를 제공하게 된다. 이는 결과적으로 검색의 성능 향상과 사용자 만족도 증가로 이어질 것으로 예상한다.
Ⅲ. 공공스톡 아카이브의 검색 지능화 서비스 적용 연구
본 장에서는 II.장에서 고찰한 검색 지능화 진화 방향의 각 측면들을 실제 공공스톡 아카이브에 적용하여 구현한 사례를 제안한다. 본 논문에서 제안하는 시스템은 ‘KBS바다’ 서비스를 통해 접근하도록 하고 ‘KBS바다’에서 검색 지능화를 경험할 수 있게 하여 ‘바다Labs’라 명명하였다.
시스템 구현은 Spring Boot 2.0이상, Spring Framework 5.3.0이상 버전을 이용하여 시스템의 확장성과 서비스의 이식성을 확보하였으며, MySQL 8.0이상 버전 적용으로 JSON Object를 활용한 정형, 비정형 메타데이터의 구조적 효율성을 확보하여 구현하였다. 시스템의 구성은 그림 1과 같다. 검색의 대상 콘텐츠로는 ‘KBS바다’에서 제공하는 소재 콘텐츠 클립 약 500개, 보도영상 소재콘텐츠 클립 약 50개, KBS에서 방송한 콘텐츠 중 저작권이 해결된 명성있는 콘텐츠 ‘KBS 명품관’ 클립 약 37개를 별도로 백엔드 시스템에 아카이브하여 실시하였다. 대상 콘텐츠는 소재 콘텐츠, 제작 콘텐츠, 취재 콘텐츠, 스토리가 있는 콘텐츠 등 다양한 형태의 콘텐츠를 포함하였다. 서비스 콘텐츠는 ‘KBS바다’와 추가 영상 업로드로 수급하였으며, 멀티모달 분석의 인공지능 기술은 ETRI에서 개발한 엔진을 사용하였다[23][24].

Proposed System Architecture for Intelligent Search Services
백엔드 시스템에는 ‘KBS바다’ 시스템에서 제공하는 콘텐츠를 조회하고, 영상과 메타데이터를 수급할 수 있는 기능과, 수급한 영상과 메타데이터를 서비스에 활용되도록 관리하는 기능, 그리고 ETRI 엔진과 API로 연동하여 영상을 전송하고, 인공지능 분석 결과를 수신하는 기능이 있다.
서비스를 제공하는 프론트 시스템의 검색 지능화 워크플로우는 그림 2와 같다. 메인페이지에 통합 검색, 1차 카테고리 검색, 추천 영상, 인기 영상을 배치하여 키워드 입력, 영상 설명 입력, 카테고리 입력으로 원하는 영상들의 리스트를 보여주거나, 최근 많이 검색되는 혹은 추천 영상을 배치하여 한 번의 입력과 클릭으로 검색 대상을 좁힐 수 있도록 하였다. 2차 검색 단계인 검색 서브 페이지에서는 좁혀진 검색 대상에서 원하는 영상이 없는 경우 추가 키워드 입력, 추천 키워드로 검색을 다양화할 수 있도록 하였다. 또한 텍스트로 추가 검색을 진행할 수 없는 경우 전체 영상 범위를 알 수 있도록 전체 카테고리 맵을 트리 형태로 보여주는 단계로 분기할 수 있도록 구성하여 영상 검색의 범위를 한 번에 더욱 좁힐 수 있도록 구성하였다.

Workflow of Intelligent Search Service Menu
제안하는 서비스에서는 II장에서 고찰한 검색 지능화 방향의 방법론 중 개인화를 제외한 방법론을 모두 포함하여 구현하였다. 또한, 사용자의 요구사항에 해당하는 프리뷰 지원이나, 저작권을 해결한 클립 등에 관한 사항도 제공한다. 구현한 검색 지능화 방법은 다음과 같다.
1. 분류체계 활용 검색 대상 축소
분류체계를 활용한 카테고리 검색을 위해 제안하는 서비스 구현 방안에서는 대표적인 스톡 아카이브에서 사용하는 분류체계를 고찰하고, 스톡 아카이브에서 많이 사용되는 분류명에 방송 콘텐츠에 적합한 분류명을 추가하여 분류체계를 생성하였다[12].
대표 스톡 서비스는 이미 많은 창작자를 사용자로 확보하고 있으며, 다수의 창작자들이 적응한 분류체계를 가지고 있다. 공통의 분류 기준을 고찰하기 위해, 표 2에서는 대표 스톡 서비스 shutterstock, gettyimages, Adobe Stock, Unsplash, Pexels에서 사용하는 카테고리명을 나열하고, 해당 카테고리명이 대표 스톡 서비스에 공통적으로 많이 나타날수록 진하게 표시하였다. 분석 결과, 80% 이상의 카테고리명이 대부분의 스톡 서비스에서 공통적으로 사용됨을 알 수 있다.
Comparison Results of Category Name Similarity in Representative Stock Video Services
분석한 방송 콘텐츠 검색의 요구사항을 기초로 정리한 카테고리는 동물, 식물, 지역/랜드마크, 신체, 사계, 음식, 특수촬영, 자연/기상, 경제/산업/일상, 유산 등 10가지 카테고리이다. 국내 제작 특성과 공공 아카이브의 성격을 고려하여, 음식, 유산 카테고리가 대표 스톡 서비스 대비 추가되었으나, 기존 대표 스톡 아카이브의 분류체계에서도 유사 카테고리가 있음을 확인할 수 있다. 작성한 카테고리는 서비스 메뉴 페이지에서는 2단계 트리 구조로 구현하여, 필요한 카테고리를 선택함으로써 검색의 범위를 신속하게 축소할 수 있도록 하였다. 그림 3에서와 같이 동물 카테고리에는 포유류, 조류, 파충류/양서류, 곤충, 어류/해양생물, 동물-기타의 하부 카테고리가 있다. 그 외 9가지 카테고리의 하부에도 상세한 카테고리를 정리하였다. 이렇게 정리된 2단계 트리 구조의 메뉴 선택으로 검색의 범위는 클립의 목록을 확인할 수 있는 상태로 축소된다.

Tree-Structured Category Selection User Interface Page
2. 메타데이터 자동 추출을 활용한 다양한 검색 정보 제공
인공지능 인식 기술을 이용해 콘텐츠의 내용에 대한 태깅을 위해 주요한 정보를 정의하면 내재 구성요소와 스토리 맥락으로 구분할 수 있다[24]. 내재 구성요소로는 샷/장면 경계와 키프레임, 객체, 장소, 시간, 배경음, 행위, 이벤트, 자막 등이 있으며, 스토리 맥락을 표현하기 위해서는 시맨틱 장면을 세그멘테이션하고, 내재 구성요소를 기반으로 시맨틱 표현의 구성요소인 인물/성별 검출, 정적 관계 추출, 감정 인식, 장면 토픽 추출, 상호 참조 인식 등의 내재 구성요소 간 시간에 따른 관계 및 상태 변화 정보를 추출한다. 내재 구성요소와 스토리 맥락으로 추출된 지능적 미디어 속성을 공공스톡 아카이브에서 사용하는 검색 키워드의 종류와 매핑하면 행위, 사물, 배경, 이벤트로 구성된다[18]. 공공스톡 아카이브에서는 특정 인물에 관련된 콘텐츠가 제한되므로, 특정 인물과 관련된 검색 키워드가 제외된다.
본 논문에서 제안하는 서비스에서도는 검색 키워드와 매핑된 지능적 미디어 속성을 추출하여 이 정보로 검색할 수 있도록 하였으며, 클립 단위 뿐 아니라 장면 단위에서도 세부 검색할 수 있도록 별도 인터페이스까지 구현하였다. 그림 2의 워크플로우에서 영상 상세메뉴에서 비디오를 클립 단위, 씬 단위로 구분하고, 클립 전체에서의 지능적 미디어 속성과 씬 내에서의 지능적 미디어 속성을 별도 타임라인 기반으로 확인할 수 있도록 구현하였다. 지능적 미디어 속성의 종류별로 별도의 타임라인을 보여주어, 각 지능적 미디어 속성의 타임라인에서 나타나는 구간을 클릭하면 해당 장면이 플레이어 상에서 보여지고 여기에 지능적 미디어 속성 부분을 바로 확인할 수 있다. 긴 영상 콘텐츠의 경우 각 씬의 대표 이미지를 클릭하면, 해당 씬의 내용을 바로 확인할 수 있으며, 해당 씬을 대상으로 보여지는 지능적 미디어 속성을 세부 확인할 수 있다. 각 장면에서 추출한 지능적 미디어 속성의 정확도도 인터페이스에서 확인할 수 있어, 추출의 성능 수치를 검토하여 검색 결과의 신뢰성을 확인할 수 있다. 본 논문에서 구현한 메타데이터 자동 추출은 멀티모달 추출 방법을 사용하였으며, 이 방법은 시간, 사물, 음성, 텍스트, 사람, 행동과 같은 변수를 중심으로 비디오에서 데이터를 추출하여 데이터를 벡터 또는 수학적 표현 후 이를 합성값으로 표현하는 방법이다[25].

Video Detailed Search User Interface Page
3. 맥락과 의도를 활용한 검색 확장
이미지와 비디오 내용의 이해 연구의 진전은 이미지와 비디오 검색을 설명 문구로 전환하여 검색할 수 있도록 하고 있어, 최근 영상 콘텐츠 검색의 방법을 획기적으로 변화시키고 있다. 본 논문에서 사용하는 비디오 설명문 추출 엔진은 비디오 설명 모델(Movie Description Model)을 사용하였다[26]. 비디오 설명 모델(Movie Description Model)은 영화의 장면 맥락을 이해하여 세부적이고 풍부한 설명을 생성함으로써 미디어 검색 서비스를 향상시키는 것을 목표로 제안되었다. 즉, 단순히 객체나 캐릭터를 식별하는 것에 그치지 않고, 장면 맥락, 위치, 그리고 행동 등 서사적 요소를 이해하고 생성함으로써 영화 설명을 개선하는 데 중점을 두었다. 이는 단순 키워드 검색에 의존하는 한계를 극복하고, 보다 정교한 설명을 바탕으로 사용자가 미디어 콘텐츠를 검색하고 접근할 수 있도록 하였다. 사용한 비디오 설명 모델은 심층 신경망 아키텍처를 기반으로, 장면 맥락 인코더(Scene Context Encoder, SCE)와 스토리 배경을 고려한 컨텍스트 디코더(Context Decoder with Story Background, CDSB) 두 개의 주요 구성요소로 이루어져 있다. 장면 맥락 인코더는 프레임에서 객체, 행동, 오디오, 배경 위치 및 시간과 같은 요소를 추출하여 장면의 컨텍스트 벡터를 생성한다. 스토리 배경을 고려한 컨텍스트 디코더는 추출된 컨텍스트를 활용하여 장면을 서술적인 방식으로 설명하는 대사와 유사한 문장을 생성한다. 기존의 비디오 캡셔닝 모델에 비해 이 모델은 장면의 위치와 시간과 같은 상세 정보를 추출하여 설명의 정확성을 향상시키고, BLEU와 CIDEr 점수에서 기존 기준 모델을 약 9% 상회하며, 실제 영화 맥락과 더 잘 일치하는 성능을 보여주었다.
그림 5에서 보듯이, 제안하는 검색 지능화 서비스의 메인 페이지, 검색 서브 페이지 상단에는 텍스트를 입력하는 질문 창이 존재하는데, 여기에는 키워드와 장면의 설명문을 모두 입력하여 검색할 수 있다. 사용자가 ‘버스가 출발하는 장면’이라는 문구를 입력하면, 이와 유사한 설명이 있는 장면을 찾아 결과를 보여준다. 영상 상세 검색 페이지에서는 타임라인의 장면 위치에 마우스를 오버하면 해당 장면의 설명문이 보여지므로, 해당 장면을 재생하지 않고도 클립 장면의 내용을 확인할 수 있는 편의 기능을 제공하였다. 타임라인에는 각 장면의 설명 내용에 대한 검색이 가능하도록 하였다.

Search Main Page and Scene Description Search User Interface Menu
Ⅳ. 서비스 사용성 분석
본 논문에서 제안하는 검색 지능화 서비스는 약 1달 기간동안 KBS 사내 테스트(8/13~8/19)와 사외 오픈 서비스(8/19~9/13)를 실시하였다. 이후, 서비스 안정성을 확인하여 현재는 1년간 한시 서비스 예정으로 오픈 중이다. 서비스 접속은 ‘KBS바다’ 사이트에 접속하는 모든 사용자들이 자유롭게 접근할 수 있도록 진입 버튼 메뉴를 노출하였다. 서비스 사용 분석은 사내 테스트에 참여한 사용자들을 대상으로 하였다. 사내 테스트에 참여한 사용자들은 서비스를 분석할 수 있는 부서의 전문가들로 구성하였다. 즉, 서비스를 분석할 수 있는 사전 지식과 경험이 풍부한 참여자들로, 콘텐츠 아카이브를 기획, 구축하였거나, 아카이브 서비스를 관리하고, 사용하는 업무를 담당하고 있다. 또한, 인공지능 기술과 서비스에 대한 연구 개발을 담당하는 참여자도 있었다.
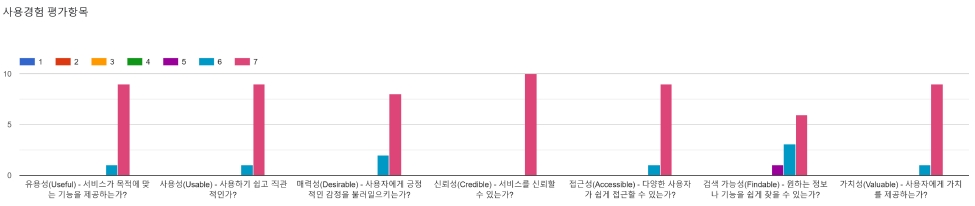
본 논문에서는 사용자 경험 평가 모델인 Peter Morville이 제안한 UX 허니콤 모델(Honeycomb Model)을 활용하여 제안하는 서비스의 사용성 평가를 실시하였다. 허니콤 모델은 사용성, 유용성, 매력성, 접근성, 신뢰성, 검색성, 가치성의 7가지 항목으로 사용자 경험을 평가하며, 5점 또는 7점 척도를 사용해 정량적으로 평가할 수 있다[27]. 각 평가 항목에 대한 평가 질문의 내용은 접근성의 측면에서 아래와 같은 질문 내용으로 작성하였다.
Comparison Results of Category Name Similarity in Representative Stock Video Services
10명의 테스트 참여자들은 사용 경험을 묻는 질문에 모든 항목에 대해 7점 만점에 6점 이상의 점수를 얻어 사용자의 경험을 어느 항목의 결손 없이 연계해 향상시키고 있음을 보였다. 주관적인 의견도 요청하였는데, 서비스에 대한 불만족 보다 인공지능 기술의 정확성에 대한 고도화 요구와 프롬프트 추천, 미리보기 템플릿과 같은 사용자에게 친절한 사용자 인터페이스와 같은 활용과 개선에 대한 요구사항이 대부분이었다. 또한, 오픈아카이브 서비스에서 더욱 많은 콘텐츠를 제공해 주었으면 좋겠다는 의견도 많아, 향후 서비스 확장에 대한 기대와 요구도 많음을 알 수 있었다. 생성형 인공지능 기술을 사용한 상용 서비스의 발전으로 많은 사용자들은 인공지능 기술에 대한 사용 경험이 있거나, 신뢰성이 있는 상태여서 비디오를 텍스트로 검색하는 검색 지능화의 진전을 긍정적으로 받아들이고 있음을 알 수 있었다.
Evaluation Results of User Experience
Ⅴ. 결 론
미디어 창작을 위해 다양한 콘텐츠를 보존하고, 제공해야 한다는 논의는 지속적으로 진행되어 왔다. 그러나 콘텐츠를 보존하고, 일련의 서비스로 제공하는 것은 재원, 운영 주체, 서비스 방법, 유지 등에서 해결해야 할 과제가 상당하여 각 부분에 대한 논의를 별도로 진행해야 할 만큼 논란의 여지가 많은 과제였다. 콘텐츠를 보존하고 이를 창작의 소재로 제공하는 서비스는 콘텐츠 제작사와 유통사를 위주로 제공되고 있으며, 창작의 과정에 도움이 되는 서비스 기능을 향상시키기 위한 연구도 진행되고 있다.
한국방송공사는 전 국민 대상으로 콘텐츠의 자유로운 활용이 가능한 무료 콘텐츠 클립 공개 서비스 ‘KBS바다’를 오픈하여 운영하고 있다. 이 서비스는 콘텐츠 제작, 학습, 교육, 연구에 짧은 고품질 소재 콘텐츠를 활용할 수 있도록 하는 오픈 스톡 서비스이다[7]. 이 외에도, 저작권을 소유하거나 해결된 명작 콘텐츠들을 다시 볼 수 있도록하는 서비스도 확대해 가고 있다. 콘텐츠의 형태, 내용, 분량 측면에서 정형화되어 있지 않고 방대한 공공 아카이브 확장 구축 시, 검색 방법에 있어 정제된 제작 정보나 편성 정보를 사용할 수 없고, 콘텐츠 내용에 해당하는 키워드를 일일이 수작업으로 입력하여 제공하는 것은 비용과 노력이 상당하여, 이를 개선할 수 있는 방법이 필요하다. 또한, 창작의 과정에서 효율적으로 아카이브가 도움이 될 수 있도록 창작자들이 요구하는 접근성 향상 방안으로 개선하는 것이 필요하다.
본 논문에서는 창작자들이 방대한 공공스톡 아카이브에서 원하는 콘텐츠 클립을 찾아 활용할 수 있는 창작자들의 요구 기능을 분석하고, 인공지능을 활용한 다양한 검색 지능화 방법론의 현황을 조사하고, 방향성을 정리하였다. 또한, 본 논문에서는 고찰한 검색 지능화의 방향성에 따라 ‘KBS바다’ 공공스톡 아카이브에 적합한 검색 지능화 방법을 제안하고 구현함으로써, 콘텐츠 접근성 측면의 검색 경험을 향상시킴을 보였다. 제안한 검색 지능화 서비스는 1) 분류 체계를 활용하여 검색의 대상을 신속하게 압축시키고, 2) 멀티모달 지능적 미디어 속성 추출 방법으로 메타데이터 자동 추출을 활용한 풍부한 검색 정보 제공하고, 3) 비디오 설명 모델을 기반으로 비디오에 대한 내용을 맥락과 의도를 반영한 텍스트로 검색할 수 있는 방법까지 지원하여 제작자들이 요구하는 원하는 씬 검색까지 가능하게 하여 검색의 정확성과 편리성을 확보하였다. 특히, 타임라인을 기반으로 한 메타데이터 확인 기능과 어느 사용 화면에서도 콘텐츠의 키워드와 장면 설명 등 텍스트를 자유롭게 입력하여 원하는 장면 검색으로 전환할 수 있고, 특정 장면의 지능적 미디어속성 추출 정확도 확인 가능한 사용자 인터페이스를 고안해 편리성을 증진하였다. 제안하는 서비스는 ‘KBS바다’ 사이트를 통해 정해진 기간 동안 누구든 접속하여 경험할 수 있도록 하여 사용성을 분석하였는데, UX 허니컴 모델에서 제안하는 서비스 사용경험의 평가 척도에서 모든 평가항목 90% 이상의 만족도를 보였다.
최근 검색 지능화의 방법은 ChatGPT를 포함한 LLM의 발전으로 획기적으로 변화하고 있다. 본 논문에서는 제안하는 검색 지능화 활용 사례는 시스템은 대표 스톡 아카이브의 사례 분석과 아카이브 사용자의 요구사항 분석을 통해 창작자들이 적응한 텍스트 검색 방안을 유지하면서, 콘텐츠 검색의 요구사항을 만족시키는 자동화된 검색 지능화 적용 사례이다. 향후, 비디오의 텍스트 기반 검색 지능화가 더욱 활성화되면, 검색에 대한 활용에서 나아가 텍스트의 요약문으로 비디오의 요약본이나 하이라이트 생성이 가능하고, 비디오 부분에 대한 제목, 주제, 관련 해시태그 등을 자동으로 생성하는 활용까지 가능할 것으로 예상된다. 또한, 사용자의 질의에 대한 축적과 대용량 언어모델을 활용하면, 개인맞춤형 비디오의 생성과 시나리오 스크립트 형태, 콘티 형태 등 다양한 출력 형태로의 전환도 용이해질 것이다. 이렇듯 검색 지능화는 생성형 인공지능 기술과 결합하여 활용에 있어서 다방면으로 확장될 것이다.
Acknowledgments
이 논문은 2024년도 정부(과학기술정보통신부)의 재원으로 정보통신기획평가원의 지원을 받아 수행된 연구임 (No.2021-0-00852, 지능적 미디어 속성 추출 및 공유 기술 개발).
References
- Robert Kyncl, Maany Peyvan, YouTube Revolution, The Quest, 2018.
- Ahn-Gu Do, “The Impact of Generative AI on the Search Market: Is AI-Driven Intelligent Search Service a Threat or an Opportunity for Media Companies?”, Newspaper and Broadcasting, Vol. 644, August, 2024.
- David Jeon, “2024 U.S. Social Media Trends,” Trends in the U.S. Content Industry, No. 16, October, 2024.
-
Hoikyung Jung, Gitaek Hyun, and Hyojin Choi, “A Study on the Effectiveness of a Broadcasting Video Archive Platform for Media Publicness: Based on McLuhan's Media Tetrad Theory,” Journal of Cyber Communication Academic Society, 41(2), pp. 177-234, 2024.
[https://doi.org/10.36494/JCAS.2024.06.41.2.177]

-
Sooyoung Kim, Shingyu Kang, and Hyojin Choi, “A Study on the Public Preservation Feasibility and Archival Needs of Over-the-Top(OTT) Content Archives in South Korea,” Broadcasting and Telecommunication Research, pp. 34-79, 2024.
[https://doi.org/10.22876/kjbtr.2024..128.002]
- Hyojin Choi, “Current Status and Implications of Domestic and International Broadcast Content Archives,” Proceedings of the Korean Society for Broadcasting and Media Conference, pp. 108-108, November, 2023. https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE1166009, (accessed Jan. 9, 2025)
- KBS bada, https://bada.kbs.co.kr, (accessed Jan. 9, 2025)
- Byunghee Jung, Wan Park, Yoonsung Lee, Haju Lee, and Sansung Kim, “Requirement Analysis for Video Archive-Based Content Search Services for Media Creation,” Proceedings of the Korean Institute of Broadcasting and Media Engineers Summer Conference, pp. 1265-1267, June, 2022. https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE1113442, (accessed Jan. 9, 2025)
-
Hoikyung Jung, Heekyung Kim, and Hyojin Choi, “User Demand Analysis for the Establishment of a Public Broadcasting and Video Archive in Korea,” The Korean Journal of Archival, Information and Cultural Studies, vol. 15, pp. 7-50, December, 2022.
[https://doi.org/10.23035/KAICS.2022.1.15.007]
- ShutterStock, https://www.shutterstock.com, (accessed Jan. 9, 2025)
- Getty Images, https://www.gettyimages.com, (accessed Jan. 9, 2025)
- Adobe Stock, https://stock.adobe.com, (accessed Jan. 9, 2025)
- Unsplash, https://unsplash.com, (accessed Jan. 9, 2025)
- Pexels, https://www.pexels.com, (accessed Jan. 9, 2025)
-
Sun-Ae Kim, “Archiving Situation and Improvement Strategy of Video Resources in Korea,” Journal of the Korean Biblia Society for Library and Information Science, vol. 20, no. 4, 2009.
[https://doi.org/10.14699/KBIBLIA.2009.20.4.131]
- TTA Standard, “Metadata Components and Format for Broadcast Content Distribution,” TTAK.KO-10.0730, 2014.
- PS Huh, WH Seok, “Defining the Role of Media in the Era of Intelligence,” ETRI Insight Report, 2019. https://ksp.etri.re.kr/ksp/plan-report/file/727.pdf, (accessed Jan. 9, 2025)
-
Byunghee Jung, Wan Park, Yunseong Lee, Bongseung Shin, Daehoon Choi, & Junghyun Kim (2024). Design and Implementation of Intelligent Search in Stock Video Archives for Media Creation. JOURNAL OF BROADCAST ENGINEERING, 29(1), 57-71, 2024.
[https://doi.org/10.5909/JBE.2024.29.1.57]
- Tips for Titles and Keywords, https://helpx.adobe.com/kr/stock/contributor/help/titles-and-keyword.html, (accessed Jan. 9, 2025)
- Selecting the Appropriate Category, https://helpx.adobe.com/kr/stock/contributor/help/categories.html, (accessed Jan. 9, 2025)
- chatGPT, https://chatgpt.com/, (accessed Jan. 9, 2025)
- Gemini, https://gemini.google.com/, (accessed Jan. 9, 2025)
-
Yongseong Cho et al., “Media and AI Technology: Media Intelligence,” ETRI Journal of Electronics and Telecommunications Trends Analysis, vol. 35, no. 5, October, 2020, presented at 2023 Korean Broadcasting Society Fall Conference.
[https://doi.org/10.22648/ETRI.2020.J.350508]
- Namkyung Lee, “Development of Intelligent Media Attribute Extraction and Sharing Technology,” Proceedings of the Korean Institute of Broadcasting and Media Engineers Conference, pp. 268-292 (25 pages), Korean Institute of Broadcasting and Media Engineers, June, 2022. https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE11134093, (accessed Jan. 9, 2025)
-
Wang, Y., Li, K., Li, X., Yu, J., He, Y., Chen, G., Pei, B., Zheng, R., Wang, Z., Shi, Y., Jiang, T., Li, S., Xu, J., Zhang, H., Huang, Y., Qiao, Y., Wang, Y., and Wang, L. InternVideo2: Scaling Foundation Models for Multimodal Video Understanding, ArXiv, 2024.
[https://doi.org/10.48550/arXiv.2403.15377]
-
JW Son, A Lee, SJ Kim and NK Lee, “Movie Description Model for Media Retrieval Services,” IEEE Trans. on Consumer Electronics, Vol. 69, No. 3, pp 296-307, Aug. 2023.
[https://doi.org/10.1109/TCE.2023.3278704]
- https://charlesamith.com/blog/ux-design/ux-honeycomb, (accessed Jan. 9, 2025)

- 1994년 2월 : 이화여자대학교 전자계산학과 학사
- 1996년 2월 : 한국과학기술원(KAIST) 전산학과 석사
- 2006년 8월 : 한국과학기술원(KAIST) 전자전산학과 박사
- 1996년 1월 ~ 현재 : KBS 미디어연구소
- 2019년 3월 ~ 2021년 12월 : KBS 미디어기술연구소 소장
- ORCID : https://orcid.org/0000-0003-2018-8277
- 주관심분야 : 멀티미디어 제작기술, 미디어 전송/서비스 기술

- 2008년 2월 : 성균관대학교 문헌정보학과 학사
- 2020년 2월 : 한국외국어대학교 정보기록학과 석사
- 2009년 2월 ~ 현재 : KBS 디지털아카이브부
- 2023년 10월 ~ 현재 : KBS 디지털아카이브부 팀장
- ORCID : https://orcid.org/0009-0009-7129-2884
- 주관심분야 : 방송기록, 메타데이터 구축, 공공 아카이브

- 2008년 2월 : 연세대학교 전기전자공학과 석사
- 2008년 3월 ~ 2017년 1월 : KBS 미디어기술연구소
- 2017년 2월 ~ 2021년 3월 : KBS 전략기획실
- 2021년 4월 ~ 현재 : KBS 미디어기술연구부 팀장
- ORCID : https://orcid.org/0009-0002-1305-3569
- 주관심분야 : 미디어 전송/서비스 기술, 멀티미디어 제작기술